Neural Networks¶
In deterministic logic programming, inference is a hard decision. When the logic gets more and more complicated, it becomes extremely sensitive and brittle. In addition, the conventional logic programming paid more attention to the context-independent logic in hope that the theorem can be generalized in any situation. This is a rather strong claim and usually does not hold for real applications. Context-dependent has been proven to be an important complimentary to symbolic representations. For example, word2vec encodes the context information into a vector for each symbol and has improved many NLP and text related tasks.
Norm is designed to combine the advantages of both symbolic and numerical representations together, i.e., compositional and contextual.
Relation expression¶
Any relation can be grounded as one neural network like the following example.
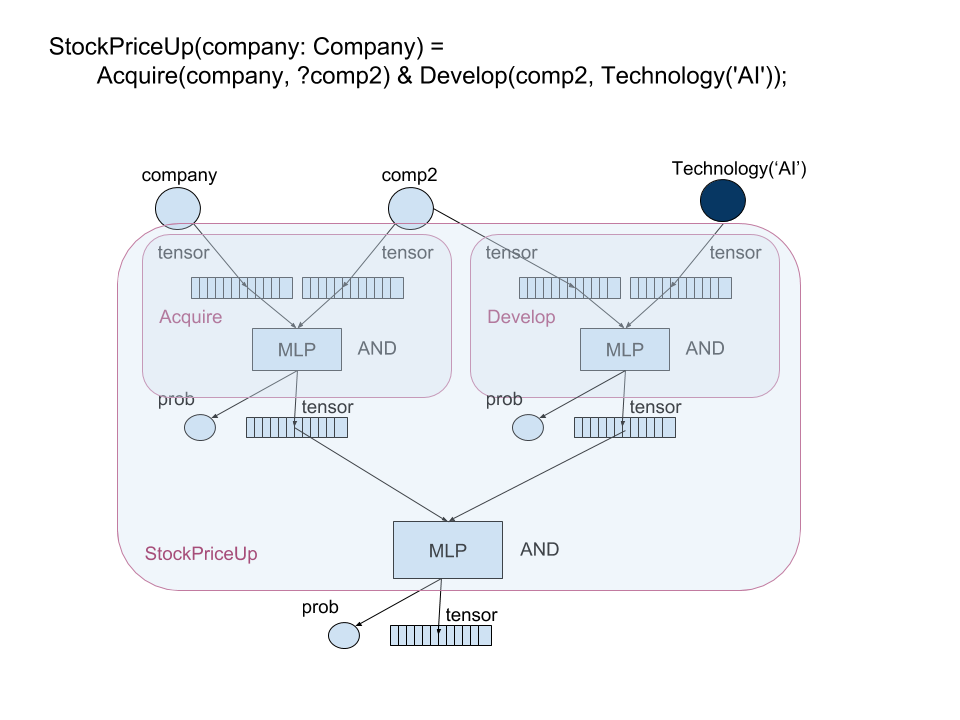
In this example, light circle represents a free or unobserved variable and dark circle represents a constant or observed
variable. We simply consider AND as a Multi-Layer Perceptron (MLP) that projects a concatenated vector into a
lower dimensional vector space that is mapped to a probability with a binary entropy loss. The tensor output of the MLP
is taken from a hidden layer.
Positive Samples¶
Assuming an open but single world, all observations are considered as positives. In addition, we can also generate positive data through distant supervision or weak supervision if explicit supervision is not available.
Negative Samples¶
To be able to build a model, one also need to sample the negatives. The entire Norm space is essentially considered as one generative model so that we can use it to sample the negatives. Different sampling algorithms will produce very different results. The followings are a few popular choices:
Random Sampling¶
neg_spu = Sample(Company()?compy & !StockPriceUp(compy), 1000);
In the beginning when StockPriceUp has no model been trained, only positive examples exist in the database. The
above logic essentially random samples 1000 companies we know and not currently in the StockPriceUp database.
Max-margin Sampling¶
` Discriminating between positive samples and random negative samples sometimes is easy and not enough to reflect the complexity of the problem. Max-margin sampling is a sampling strategy to generate samples close to the positives such that the model can be sophisticated to model the subtle differences.
neg_spu = Max(Company()?compy & StockPriceUp(compy)?spu & spu.label != 1, 1000);
The above example will pick the 1000 companies whose stock price is the Most Possibly Up but not labeled.
Generative Adversarial Network¶
Max-margin sampling algorithm assumes that the sampled negatives are true negatives. Otherwise, the optimization algorithm will try to overfit a model to distinguish two positive samples. To avoid this situation, an advanced GAN style algorithm can be applied to build a generative model to sample both the negatives and the positives and a discriminative model to decide which one should be included into the optimization or not.
Active learning¶
With all these semi-supervised or weakly supervised learning methods, we should be able to leverage the single open world to access unlimited samples. As a result, Norm is able to build a good model even with small number of positive samples. However, to push the model accuracy to the really high confidence, one might need help from the active learning to verify the positive/negative labels with minimum efforts to achieve the best generalization capability.